
美光財報的重點?巨頭發起光通訊新憲法?微軟提告OpenAI和亞馬遜?- KP思考筆記(第34期)


大家好,我是 KP。歡迎來到第 34 期的《週末思考筆記》。
這段時間,市場依舊籠罩在不確定性之中。既沒有出現足以讓人興奮「抄底」的大幅回撤,也沒有明確的單邊趨勢,大體上維持著觀望的格局。
但「沒有操作」並不代表「沒有作為」。
投資的大部分時間,其實都應該花在思考與學習上。當市場靜止時,正是我們修煉內功、補齊認知拼圖的最佳時機。
本週發生的事情其實非常多且關鍵:從 Nvidia 的 GTC 大會、光通訊盛會 OFC、美光的財報,到卡達 LNG 廠意外等事件。這些看似散亂的點,背後都隱藏著值得深挖的產業邏輯。
隨著研究院的社群日益壯大,我常在留言區或投票中看到新加入的朋友敲碗,希望能分析某些特定的行業或公司。看到大家對知識的渴求,我其實非常欣慰,這也證明了我們這裡聚集了一群同樣重視深度思考的人。
不過,我也發現一個有趣的現象:有些大家想我討論的主題,其實我在幾個月前已經做過「深入分析」了。
這正是我想跟大家分享的一個「閱讀小訣竅」:
不要把這裡當作一般的週更報紙,看過就丟;請把它當作一座不斷擴充的「投資圖書館」。
這涉及到我對「FOMO 研究院」的定位。在投資圈,最常見的模式是「KOL 導向」:某個大師認為時機已到,號召粉絲進場。
這種模式追求的是及時性,但缺點也顯而易見:兩週前的分析,到了今天可能就成了過時的廢紙。
但我追求的,是另一種極致。
我寫的每一篇深度分析,往往長達兩萬字甚至更多。我知道這很長,甚至有點「硬」,但我的初衷是為了打造「長青內容」。
因為我想做的,不是追逐表象的資訊,而是將一個行業的商業模式從底層到表層、從宏觀到微觀的投資邏輯徹底拆解。我們討論計價模型、分析 Bull Case(牛市情境)與 Bear Case(熊市情境),是為了讓你真正「看懂」一家公司。
我的目標是:即使你在半年、一年後重新翻閱,這份報告依然具有強大的參考價值。
在我的邏輯裡,投資的本質是買入一家好公司並分享其成長成果。而要拿得住、敢重倉,前提是你對它的邏輯有著堅不可摧的理解。
因此,研究院的運作邏輯是:用「極深度分析」為大家打好不同產業的地基;再透過每週的「週末筆記」追蹤新進展,不斷驗證或修正原本的推論。
這就是為什麼你會在筆記中看到大量的往期連結,事實上,我自己也經常重溫過往的分析,因為那些底層邏輯是不會輕易改變的。
所以,當你成為會員的那一刻,你得到的並不只是「下一篇」分析,而是立刻解鎖了整座知識庫的鑰匙。
如果你是剛加入的朋友,我非常推薦你往回探索。那些過往的產業拆解,往往就是理解當下市場波動最好的「導讀手冊」。你會發現,很多現在看似混亂的市場訊號,其實早就在過往的邏輯框架中預演過了。
這裡的價值,不在於我每個星期為大家「喊單」,而在於我們共同建立的這個不斷增長的深度投資資料庫。
通過持續的學習、重溫與驗證,我們對世界運作的理解會越來越通透。你未必能在一時三刻間消化所有內容並立刻發財,但請相信我,這種「認知複利」,才是長久且穩定獲利的唯一捷徑。
這才是訂閱「FOMO 研究院」真正的意義:你買的不只是一時三刻的資訊,更是時間與認知的複利。
本週,讓我們繼續透過 6 個主題,完善我們的認知地圖:
主題一:Grok準備拜師華爾街精英?
主題二:毛利率 81%,美光不再是週期股了嗎?
主題三:微軟準備提告OpenAI和亞馬遜?
主題四:光通訊新憲法,巨頭發起的OCI聯盟是為了重新定義規則?
主題五:Nvidia是如何做到一年一更的?
主題六:為何黃仁勳要盛讚OpenClaw?
主題一:Grok準備拜師華爾街精英?

根據報導,xAI正在大規模招聘華爾街的銀行家、信貸專家和交易員。但並非為了傳統的融資或併購,而是邀請他們成為AI模型Grok的「私人導師」。
這一步棋,表面上看似在追趕競爭對手,但深究其內核,這其實是Elon Musk典型的「第一性原理」體現。發現此路不通後,迅速切換到一條更具實驗性、也更有趣的新路徑。
從「推倒重來」到「大腦移植」
要理解這次招聘的深意,必須先看xAI近期的「大動作」。2026年3月初,馬斯克公開承認:「xAI的初版架構是錯的,我們正在從地基開始重建。」伴隨而來的是創始團隊的大換血,以及代號為「Macrohard」的宏大專案被廢棄。
這說明馬斯克意識到,單純靠增加算力、餵養海量網路數據的「通才教育」,在面對極度嚴謹的專業領域時,效率低得驚人。於是,他選擇了另一條路:直接為Grok進行一場「專業大腦移植」。
讓我們用第一性原理來思考:打造一個頂級金融AI的目標是什麼?不是讓它背誦全世界的財報,而是讓它能像一位經驗豐富的投資銀行家那樣去「思考」和「推理」。
傳統路徑是「餵養」海量數據,期待智慧「湧現」,這條路成本高昂且充滿不確定性。馬斯克顯然在問一個更根本的問題:既然目標是模仿專家的思維,為何不直接讓專家來「教」呢?
這就是xAI正在做的事。聘請這些金融專家,其任務不是處理報表,而是將他們數十年積累的、無法量化的「金融直覺」與「決策邏輯」,例如如何分析一筆槓桿收購的風險、如何為複雜的資產抵押債券(CLO)定價,轉化為AI可以理解和學習的「思維步驟」。
這是一場知識萃取工程,一場「數位學徒制」的實驗。AI不再是圖書館,而是成為了頂級專家的學徒。這就像武俠小說裡的「真氣灌頂」,繞過了數十年的苦修,押注於「知識的品質」遠勝於「數據的數量」。
為何金融是這條新路徑的「灘頭堡」?
馬斯克選擇金融作為突破口,我認為有兩個原因:
容錯率極低的價值高地:金融是錯誤成本最高的領域,一個小數點的偏差就是數百萬美元的損失。如果Grok能在這種高壓環境下提供可靠的推理,其商業價值將直接對標企業級服務的高額利潤。
挑戰「彭博霸權」:結合X的即時資訊流,一個精通金融推理的Grok將變得極度強大。它不再只是個聊天機器人,而是一個能即時分析市場傳聞、模擬交易策略的「決策副駕」。這是在以一種更具互動性、成本更低的方式,挑戰Bloomberg Terminal的護城河。
身為金融人,我為何感到興奮而非恐懼?
坦白說,作為一名金融從業者,我對目前市面上通用AI的表現一直抱持著「謹慎使用」的態度。
雖然現在的AI已經能做摘要、跑數據,但如果你真的把它產出的研究報告拿來決策,你會發現其品質依然相當「平庸」。在大多數情況下,它們的洞察力頂多與一名剛入行的初級分析師(Junior Analyst)持平,甚至在處理複雜邏輯或捕捉市場微妙情緒時,表現得更差,還伴隨著令人頭痛的「幻覺」問題。
這也是為什麼我對xAI這次的「導師計畫」期待的原因。
我期待的不是一個更快的「搜尋引擎」,而是一個能真正理解「金融邏輯」的推理機器。
如果馬斯克的這場實驗能成功,我預見到它將解決目前金融AI的三大痛點,徹底改變我的工作流程:
從「平庸摘要」進化為「深度洞察」:目前的AI只是在做文字搬運,缺乏「So what?」的判斷。我期待經過華爾街專家調教後的Grok,不再只是羅列財報數據,而是能告訴我:這筆債務結構的變動,對公司未來兩年的現金流會產生什麼連鎖反應?這才是真正能解放判斷力的工具。
從「初級分析師」進化為「超級副手」:如果Grok能透過「數位學徒制」學會專家的思維路徑,它將從一個需要被時刻盯著的「實習生」,變成一個全天候、不知疲倦、且具備專家級常識的「超級副手」。
高品質的壓力測試與模擬:當我構思一個投資策略時,我希望AI能在幾秒鐘內模擬數千種極端情景。這在過去需要一個量化團隊花費數天,而未來,這可能只是與Grok的一場對話。
最終,這場變革的結局不會是「AI vs. 人類」,而是「懂得駕馭 AI 的金融專家 vs. 固守傳統的金融專家」。
我並不擔心被取代,因為真正的投資決策,往往發生在數據的盡頭——那是對人性野心的洞察,以及在關鍵時刻承擔風險的勇氣。
AI戰爭的終局,從「通才」到「專精」的勝利
xAI的轉向為整個產業投下了一顆震撼彈。它預示著,通用型大語言模型的競爭可能已接近天花板,下一個戰場將是「專精模型」的對決。
馬斯克在承認初期失敗後,選擇了一條更艱難、但可能更具顛覆性的道路。這場實驗的成敗,不僅決定了Grok能否成為金融界的終極武器,更揭示了AI戰爭的新趨勢:最後的贏家,可能不屬於擁有最多數據的人,而屬於那些能將人類頂級智慧最有效地「萃取」進模型裡的玩家。
這場「數位學徒制」的實驗才剛開始,而我已經迫不及待想看看,這位拜華爾街為師的Grok,最後能進化到什麼程度。
主題二:毛利率 81%,美光不再是週期股了嗎?
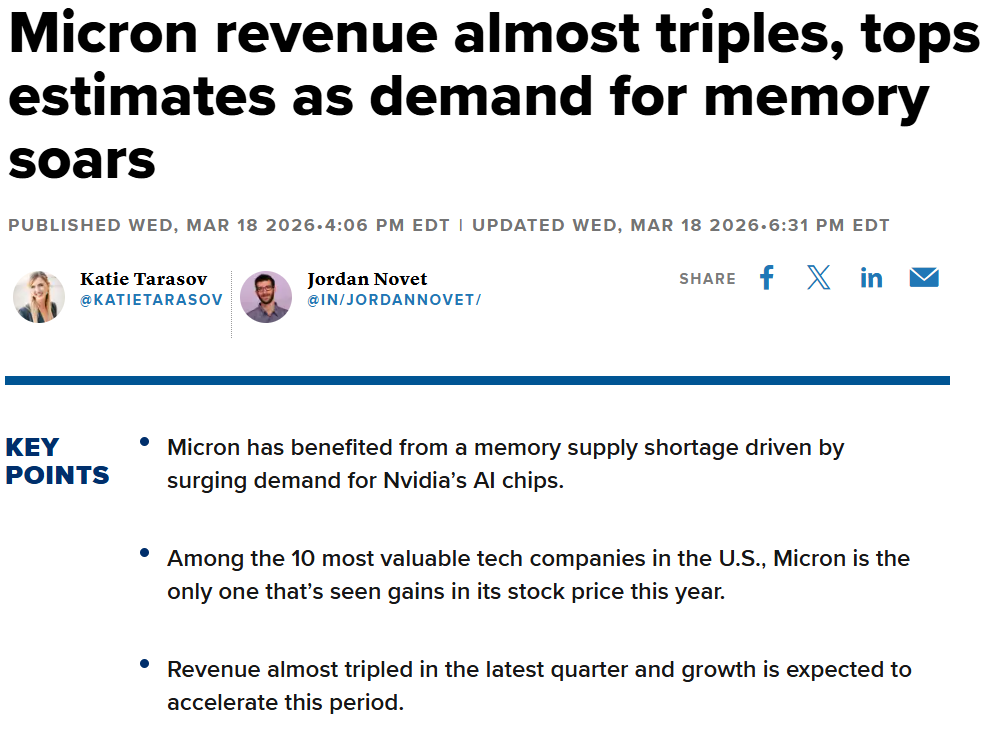
美光剛交出的這份財報,數字漂亮得讓人心驚膽顫。Non-GAAP毛利率 74.9%,下一季指引直接喊到81%。
你要知道,這家公司過去十年的毛利率中位數只有40%不到。在記憶體這個曾經被視為「大宗商品」(Commodity)的慘業,這種利潤率簡直是外星科技。
但作為投資者,我們永遠要學會雞蛋裡挑骨頭。在全市場狂歡時,我們得冷靜問一句:這潑天的富貴,到底能拿多久?
「全線通脹」的紅利
當大家看到這個數字,第一反應通常是:「喔,肯定是HBM(高頻寬記憶體)賣得太好了,NVIDIA的訂單嘛,可以理解。」
但事實上,美光目前毛利率最高的產品,竟然不是 HBM,而是那些看似平凡的DDR5和手機用的LP DRAM。
看看各部門的毛利率就知道有多誇張:
手機與PC部門:79%(你沒看錯,就是你我手機裡那顆,利潤率最高!)
雲端與資料中心部門(含HBM):74%
車用與嵌入式部門:68%
這說明什麼?這不是單一產品的勝利,而是一場由AI引爆的、席捲整個產業的全面性缺貨。由於AI伺服器把大量的產能(特別是先進製程)吸走,導致從傳統伺服器、高階PC到智慧手機,所有領域的記憶體供應都極度緊張。
客戶的需求滿足率只有50%-66%,等於是客戶拿著現金排隊,還只能買到一半的貨。在這種賣方市場下,美光對所有產品線都擁有了絕對的定價權。
五年「鎖喉式」合約登場
好,既然是全面缺貨,那歷史告訴我們,半導體是個週期性產業。一旦新的產能開出,價格就會崩盤,好日子很快就結束了。2018年的記憶體大崩盤,大家還記憶猶新。
美光管理層顯然也知道你在擔心什麼。於是,他們祭出了一個大殺器,試圖告訴市場:「這次,真的不一樣了。」
這個殺器,就是「策略性客戶協議」(SCA, Strategic Customer Agreement)。
過去的LTA通常只簽一年。說白了,就是個「君子協定」,市場好的時候大家遵守,市場一變差,客戶隨時可以找理由砍單或重新議價,約束力很弱。
但現在,美光簽下的第一張SCA,長達五年。這是一份包含具體數量和定價承諾的多年期合約。
這意味著什麼?
這意味著,美光正在和它的大客戶玩一場「膽小鬼遊戲」。美光說:「我要砸超過250億美金蓋新廠,你敢不敢跟我綁定五年的訂單,保證未來五年都跟我買?」而客戶為了確保在未來幾年AI軍備競賽中不斷糧,只能咬牙簽下去。
這份五年合約,將客戶的未來需求與美光的產能擴張計畫死死綁在一起。它給了美光前所未有的底氣,敢於進行巨額的資本支出,因為未來的訂單已經部分鎖定。這也是管理層敢拍胸脯保證「供應緊張會持續到2026年以後」的核心原因。
那份「機密」合約裡藏著什麼?
不過,在狂熱的市場中,我們必須要嘗試雞蛋裡挑骨頭,盡量挑戰自己的假說。
當分析師在法說會上追問這份SCA的具體條款時,例如:「如果市場崩盤,客戶可以取消訂單嗎?」「有懲罰條款嗎?」「定價是固定的還是浮動的?」
美光管理層的回答,永遠是那幾個字:「合約是穩固的,但細節是機密的。」
這就是關鍵所在:這場高達250億美元的資本支出(CAPEX)豪賭,究竟是「有恃無恐」還是「孤注一擲」?
如果這份 SCA 在法律上具有真正的強制約束力,那麼美光瘋狂擴產就不是盲目跟風,而是精準的產能投放;這 250 億美元的支出,將成為未來五年穩定獲利的墊腳石。反之,如果合約在極端市況下仍有轉圜餘地,那麼現在的 CAPEX 競賽,就可能演變成下一場產能過剩的導火線。
記憶體產業的「無罪推定」
我們正在見證記憶體產業從「週期股」能否轉向「結構性成長股」的關鍵時刻。接下來的觀察重點很明確:是否會有更多大客戶跟進簽署長達五年的 SCA?合約細節是否會隨著時間推移而更加透明?
在投資的世界裡,記憶體產業目前處於一種「無罪推定」的狀態。在證據證明它崩盤之前,我們都必須承認這場記憶體盛世是真實且強大的。
主題三:微軟準備提告OpenAI和亞馬遜?

微軟(Microsoft)和OpenAI的故事,可以拍一套矽谷的狗血劇。
故事要從 2019 年說起。那時的 OpenAI 還是個燒錢的非營利組織,微軟像是個眼光獨到的「早期投資人」,豪擲十億美金定下盟約。當時的協議很簡單:我給你錢和算力,你給我技術和獨家。
然而,隨著 ChatGPT 的爆發式成長,這段關係發生了質變。OpenAI 對算力的胃口變成了「無底洞」,即便強如微軟,也發現自己無法(也不太想)獨自承擔那天文數字般的基礎設施支出。
於是,在 2025 年底,雙方重新修訂了「婚前協議」,正式進入了一種「開放式關係」。微軟放棄了對算力的獨家供應權,允許 OpenAI 去外面找別的「乾爹」(如 Oracle、亞馬遜)買算力,前提是微軟依然得是那個「正宮」(核心 API 必須留在 Azure)。
但顯然,OpenAI 這次玩得太過火了,直接觸碰了微軟的底線,氣得「正宮」考慮直接法庭見。
什麼是「有狀態」的技術漏洞?
根據微軟與 OpenAI 在 2025 年底更新的合約,微軟的 Azure 擁有 OpenAI 「無狀態 API」(Stateless API) 的全球獨家託管權。簡單來說,如果你只是傳一個指令給 AI,它回傳一個答案(不記得你是誰,也不存留上下文),這就是「無狀態」,必須走 Azure。
然而,OpenAI 與亞馬遜正在玩一個「文字遊戲」:他們為新產品 Frontier 開發了一種「有狀態運行環境」(Stateful Runtime Environment, SRE)。
微軟的邏輯:
「只要是用我的模型出的產品,管你有沒有狀態,都得在 Azure 上跑!」
OpenAI 的邏輯: 「合約只說『無狀態 API』歸你,但我現在做的是具有長期記憶、能自主運行的 AI 代理(Agents),這不屬於 API 範疇,所以我可以在亞馬遜的 AWS 上跑。」
這就像一對夫妻簽了婚前協議,規定「所有在外面賺的薪水都要存入共同帳戶」。結果一方說:「但我現在賺的不是薪水,是投資分紅,所以可以存進我自己的帳戶。」
一位接近微軟的消息人士對《金融時報》表示:「我們很清楚我們的合約。如果他們違約,我們就會告他們。如果亞馬遜和OpenAI想賭一把他們律師的創造力,我會賭我們贏,而不是他們。」
OpenAI 為什麼非要亞馬遜不可?
為什麼 OpenAI 冒著撕破臉的風險,也要投奔亞馬遜的懷抱?答案只有兩個字:算力。
雖然微軟承諾了高達 2,500億美元的算力支持,但 OpenAI 的胃口是無底洞。亞馬遜這次不僅掏出 500億美元現金,還拿出了殺手鐧:高達 2GW(吉瓦)電力支撐的 Trainium 系列自研晶片。
對於 OpenAI 來說,過度依賴微軟的 Azure 是一種戰略窒息。透過與 AWS 合作,OpenAI 不僅獲得了更多樣化的晶片供應,還能直接觸及那些「非 AWS 不用」的企業巨頭。這是一次赤裸裸的「去微軟化」行動,宣告 OpenAI 不再甘於只做微軟的 AI 插件。
誰才是最後的贏家?
這場爭端揭示了一個殘酷的現實:在 AI 時代,「獨家協議」可能只是一張隨時會被重新定義的廢紙。
當技術進化的速度快到法律條文追不上時,企業總能找到定義上的「漏洞」來規避約束。OpenAI 試圖證明自己是獨立的平台,而微軟則試圖守住它用百億美金築起的護城河。
這場糾紛的最終結果,大概率不會是法庭見,而是一個「技術性妥協」。微軟可能會允許 OpenAI 在 AWS 上運行部分業務,但代價是亞馬遜必須支付高昂的「過路費」給微軟,或者 OpenAI 必須保證 Azure 擁有更優先的功能更新權。
這場「500 億美元的法律博弈」告訴我們:在 AI 賽道上,沒有永遠的盟友。即便曾經深愛過,在算力與數據主權面前,大家隨時準備翻臉。
主題四:光通訊新憲法,巨頭發起的OCI聯盟是為了重新定義規則?

今年的光通訊大會(OFC 2026),三份關乎AI未來基礎設施的協議橫空出世,它們分別是OCI、XPO與Open CPX。如果用一個比喻來理解,這三者分工明確:
OCI (Optical Compute Interconnect):決定了光訊號的「靈魂」,也就是它該「說什麼語言」。
XPO (eXtra-dense Pluggable Optics):定義了「當下」光模組在機器外部該如何插拔。
Open CPX (Open Co-packaging):規劃了「未來」光引擎在晶片旁該如何安裝。
在這三者之中,OCI無疑是最根本、最核心的底層協議。讓我們深入拆解,這部「新憲法」究竟寫了些什麼。
矽光子的「通用語言」
過去,當我們談論 CPO(共同封裝光學)或機架間的光學連接時,各家廠商(如 Coherent, Lumentum)都有自己的「獨門秘籍」。
對微軟、Meta 這些大買家來說,這簡直是噩夢:萬一選錯了技術路線,或是被單一供應商鎖死,議價權就落在了光學公司的手中。
為了解決這個困境,OCI聯盟應運而生。在OCI聯盟的第三個目標中,已經說得十分明確:「確保一個可擴展的、多供應商的AI供應鏈……避免供應商鎖定(vendor lock-in)。」
這句話翻譯過來就是:我們(買家和晶片巨頭)要拿回定價權與選擇權。
一部由買家寫下的「通用語言」
OCI就像為AI世界的數據傳輸,制定了一套「通用的USB標準」,其核心是從「模組中心」轉向「矽晶中心」(Silicon-centric)的遊戲規則:
制定通用語言:透過統一使用NRZ調變、WDM波分復用、單根光纖雙向傳輸等具體技術,OCI定義了一套所有人都必須遵守的開放「語言」。任何供應商,只要你的產品能「說」這門語言,就能進入市場。
物理級的暴力瘦身:這套新語言帶來了驚人的效率。它讓光引擎能更緊密地與晶片(GPU/ASIC)整合,將原本銅纜連接所需的約30W功耗,直接砍到9W。在未來「吉瓦級」功耗的AI資料中心裡,省下的每一瓦都是純利潤。
重塑連接的想像:它讓光學不再是外掛的線纜,而是晶片延伸出去的「神經末梢」,極大地降低了延遲、提高了密度,為更大規模的AI集群掃清了物理障礙。
誰制定規則,誰就贏得未來
當物理層被標準化後,它就不可避免地走向「商品化」。買家可以自由地從多家供應商採購符合OCI標準的光學引擎,進行混合搭配。供應商之間必須靠成本、效能和規模化能力來競爭,而不是靠專有的「護城河」。
遊戲規則制定者,徹底變了。
看看OCI MSA的創始成員名單:AMD、Broadcom、Meta、Microsoft、NVIDIA、OpenAI。
這份名單極具深意,裡面有最強的晶片設計者(NVIDIA、AMD、Broadcom),有最強的算力需求方(Meta、Microsoft),甚至還有AI的靈魂(OpenAI)。唯獨不見任何一家傳統的光學元件大廠。
這釋放了一個再清晰不過的訊號:「規格,由我們這些蓋工廠、用算力的人來定;你們供應商,照著做就好。」
從「手工藝品」到「工業革命」
除了制衡供應商,OCI更宏大的使命,是為整個產業的「工業化大爆發」鋪平道路。
歷史一再證明,任何技術只要還處於「各說各話」的階段,就無法真正規模化。如同鐵路若沒有統一軌距,火車便無法跨國行駛;貨櫃若沒有標準化,全球貿易就不可能如此繁榮。
OCI這門「通用語言」的確立,意味著周邊的測試設備、封裝材料、自動化產線都能圍繞著這個標準去開發。
這種「確定性」將吸引海量資本湧入,把過去昂貴、客製化的「光學手工藝品」,轉化為可大規模量產的「工業標準品」。
當巨頭們大舉興建AI工廠時,他們需要的不是幾千個昂貴的精品,而是數百萬個標準化、高良率的組件。OCI,正是為了這「百萬級產能」而生。
「光學大航海時代」的起點
那麼,Coherent、Lumentum這些傳統光學巨頭會是輸家嗎?不,這場革命的重點在於「做大蛋糕,再重新分配」。
OCI的標準化極大地加速了整個產業向光學互連的遷移,創造了一個數千億美元級別的全新市場。Coherent和Lumentum作為外部光源(ELS)、雷射等核心技術的領導者,依然是新秩序下最重要的玩家。NVIDIA等巨頭早已向它們簽下數十億美元的雷射供應預訂單,證明了它們的不可或缺。
不同的是,它們的獲利模式必須改變。它們不再能依靠專有技術鎖定客戶來獲取超額利潤,而是必須在一個更開放、更透明的市場中,憑藉其卓越的製造工藝、規模化能力和成本控制來贏得海量訂單。
根據OCI的路線圖,GEN1(200G)已然就緒,未來直指1.6T乃至3.2T。這預示著,2026年是技術定調之年,而從2027年開始,我們將正式迎來AI集群全面「光學化」的爆發元年。OCI,就是這場「光學大航海時代」的起始羅盤與統一海圖。
主題五:Nvidia是如何做到一年一更的?

在GTC大會演講後,黃仁勳留下來回答了分析師的問題。事實上,每次Q&A的內容都十分豐富,而其中一個對話我特別想和大家分享。
有分析師問到,為什麼 Nvidia 能在員工人數沒有爆炸式增長的情況下,維持一年一更(Blackwell 到 Rubin)這種近乎瘋狂的產品節奏?
黃仁勳的答案是,因為他們「全棧擁有」(Full-Stack Ownership)整個產業鏈。
重新定義戰場:數據中心才是「最小單位」
過去我們評估半導體,看的是單顆 CPU 或 GPU 的效能。但在 AI 時代,黃仁勳看得很透徹:現在的運算單位不再是那顆晶片,而是整座「數據中心」。
當對手還在埋頭設計一顆更快的晶片時,Nvidia 已經在設計整座工廠。這包括了晶片、網路交換器(Networking)、存儲架構、散熱機櫃,甚至是運行這一切的軟體堆棧(CUDA)。
如果你只做晶片,而網路要等 A 公司、散熱要等 B 公司、軟體要等 C 開發者,你注定會陷入整合地獄。只要其中一個環節延遲六個月,你的整個系統就過時了。
Nvidia 這家公司,本身就是一顆「晶片」
我特別感興趣的是黃仁勳的組織管理,他提到自己有 60 位直接下屬。
這其實是「康威定律」(Conway’s Law)的極致體現。這個定律告訴我們:一個公司設計出的產品架構,最終會反映其組織的溝通結構。
你可以把整個 Nvidia 想像成一顆巨大的「超級晶片」。
黃仁勳本人就是這顆晶片的「中央控制單元」,而他那 60 位直接下屬,就像是環繞在核心周圍的高速處理單元。
在傳統公司,訊息傳遞要經過層層官僚(就像充滿延遲的電路板);但在 Nvidia,負責散熱、網路、晶片、軟體的頭頭,全部直接對接核心。
這種「扁平到極致」的架構,確保了所有人都在同一個頻率上運作。當黃仁勳決定要衝刺 Rubin 架構時,這顆「公司晶片」內部的所有組件會同步共振,沒有資源爭奪的內耗,只有 100% 的執行力。
新車試火,一轉鑰匙就要發動
在硬體工程中,最令人屏息的時刻叫做「Bring-up」,也就是新產品第一次通電、嘗試運行軟體的瞬間。
這就像是你手工打造了一台超跑,第一次插進鑰匙、按下啟動鍵。如果引擎是 A 牌、變速箱是 B 牌、電腦系統是 C 牌,當車子發不動時,你根本不知道是誰的問題。對手通常要花幾個月甚至半年,才能在這種「拼裝車」裡找出 Bug。
因此,黃仁勳說到:「如果你是從各家拼湊新技術,你怎麼可能做到每年『Bring-up』一次?」
因為 Nvidia 擁有從底層網路編譯器到上層 AI 模型的全部技術,他們在設計硬體時,軟體就已經在模擬環境裡跑過千萬遍了。
這意味著當 Blackwell 晶片第一次通電時,它不是在「嘗試運作」,而是「準備起飛」。這種同步開發的能力,是每年更新產品的門票。
消除 500 億美金的恐懼
這引出了最終極的護城河:軟體連續性。
當微軟、AWS 或 Google 斥資數百億美元購買 NVIDIA 硬體時,他們是在進行一場巨大的商業豪賭。他們需要這批昂貴的設備在通電的瞬間,就能開始產生 Token(也就是錢)。
NVIDIA 的 CUDA 平台為此提供了「零風險」保證。黃仁勳說:「第一天,我把昨天的軟體放到新系統上。如果跑不動,那還有什麼意義?」
NVIDIA 的客戶可以將 Hopper 上的代碼原封不動地拿到 Blackwell 上運行,立即獲得數倍的性能提升。這對手來說是無法想像的,他們需要說服整個生態系為其新硬體重寫軟體。
要在 12 個月的週期內,同時完成晶片、網路、散熱與軟體的同步進化,你必須擁有每一個拼圖塊。如果你還在依賴第三方供應商的進度,你根本無法進入這場光速競賽。
主題六:為何黃仁勳要盛讚OpenClaw?

(這是Nvidia官網上的圖)
「人類歷史上最成功的開源專案」、「下一個 ChatGPT」
這些聽起來極其浮誇的讚譽,出自 NVIDIA 執行長黃仁勳之口,但他稱讚的卻不是自家的產品,而是 2026 年全球最火熱的開源專案:OpenClaw。
為什麼黃仁勳這麼興奮?因為 OpenClaw 標誌著 AI 從「會聊天的機器人(Chatbot)」進化到了「會幹活的代理人(Agent)」。
AI 的「Windows 時刻」:當 Agent 變成 OS
黃仁勳在會上說了一句話:「OpenClaw 是個人 AI 的作業系統。」
過去我們用 Windows 或 Mac 操控電腦,那是「人機互動」;但在 OpenClaw 的世界裡,電腦的最小單位不再是 App,而是 “Claw”(爪子/代理人)。這些 Claw 24 小時在線,它們會自己翻瀏覽器、寫代碼、進資料庫、改 Bug,甚至會跟其他 Claw 開會協作。
你不再是「操作」電腦,你是「管理」一群專業團隊。這就是黃仁勳預言的 AaaS(Agent-as-a-Service)。未來的軟體公司如果沒有 OpenClaw 策略,就像在網路時代沒有網頁一樣,注定會被邊緣化。
OpenAI 的天才與 NVIDIA 的肌肉
這裡有個很有趣的背景:OpenClaw 的創始人 Peter Steinberger 在今年二月被 OpenAI 挖角了,但他堅持讓 OpenClaw 保持獨立基金會運作。
這就形成了一個局面:OpenAI 出人(技術靈魂)、NVIDIA 出力(硬體與安全架構)。
這也是為什麼黃仁勳敢在台上瘋狂推銷一個「別人家」發起的開源項目。因為他看準了:只要 OpenClaw 成為標準,全世界的 Agent 都要跑在 NVIDIA 的晶片上。
NemoClaw:給「瘋狂代理人」裝上安全帶
OpenClaw 雖然強大,但它有個致命傷:安全。一個能自主改代碼、進系統的 AI,萬一「跑路」了怎麼辦?企業敢用嗎?
這就是 NVIDIA 推出 NemoClaw 的原因。這不是 OpenClaw 的競爭對手,而是它的「企業級防彈衣」。
隔離沙盒(Sandbox):透過NVIDIA新發布的OpenShell™運行時,給予「爪牙」一個安全的活動空間,讓它能發揮作用,卻無法傷害到核心系統。
策略護欄(Guardrails):制定嚴格的規則,明確「爪牙」能做什麼、不能碰什麼,確保其行為合規可控。
隱私路由器:智慧地判斷任務的敏感性,將涉及隱私的工作留在本地處理,只在安全的情況下調用雲端模型。
黃仁勳的戰略是:OpenClaw 負責「病毒式擴擴散」佔領市場,NemoClaw 負責「收編企業」建立護城河。它解決了OpenClaw最大的痛點,將一個「好玩但危險」的專案,轉化為一個「強大且安全」的企業級解決方案。
用「開放」鎖死「未來」
黃仁勳為何不大力推廣自家的閉源方案,反而去擁抱一個獨立的開源專案?答案就在於「做大蛋糕,再定義遊戲規則」。
用「開放」瓦解對手: 透過全力支持 OpenClaw 這個開放標準,NVIDIA 確保了「AI 作業系統」這一層不會被微軟或 Google 等軟體巨頭壟斷。當所有人都在同一個開放平台上開發時,封閉的軟體護城河就不復存在。
用「安全」鎖定價值: 在開放的戰場上,NVIDIA 提供了最關鍵的增值服務——NemoClaw。雖然它也是開源的,但它深度整合了 Nemotron 模型與 OpenShell,並針對 RTX、DGX 等硬體進行了極致優化。
這形成了一個商業閉環:NVIDIA 鋪設了免費的高速公路(OpenClaw),但同時成為了這條路上唯一官方認證的「安全服務商」與「性能改裝廠」(NemoClaw + GPU)。
「永遠在線的代理需要專用的計算能力(Always-on agents need dedicated computing)」。NVIDIA 的官方聲明揭示了其核心盤算:這些 7x24 小時運行的「爪子」,將會持續不斷地消耗算力。這不僅是技術的革新,更是對硬體需求的永久性拉動。
AI 的戰爭,已經從「模型參數」的軍備競賽,正式轉向關於「代理(Agent)生態」的掌控權之爭。
最後,跟大家分享一個新的內容安排。
大家可能知道,我在一個多月前受邀於《商業周刊》開設了獨家專欄。商周極少對外開放專欄作者的席位,能獲得這份邀請,對我來說是極大的肯定。
根據我與商周的合作協議,這些文章在刊登「一個月後」,就可以正式解禁,分享給我們 FOMO 平台的付費會員。未來,我計畫「每兩期」就會在電子報中為大家精選並放上這些專欄文章。為了不轟炸大家的信箱,我不會為這些解禁文章單獨發送 Email。
如果你本身已經有訂閱商周,我也很推薦你點開下方的連結看看。因為商周刊登的版本有經過編輯部的精簡與潤飾,而我放在這裡分享給你們的,是「原汁原味的未刪減原稿」,讀起來絕對會有截然不同的風味!
你可能會想:「一個月前的文章,現在看不會太過時嗎?」
如果你追蹤我夠久,就會知道我寫作的核心一直都是拆解「底層的商業邏輯」,而不是追逐短期的時效性新聞。因此,這些產業鏈的結構性分析,即使過了一個月,含金量依然不減,甚至能讓你用更宏觀的視角來驗證市場的發展。
文章連結就放在下方,祝大家閱讀愉快!👇
感謝分享。之前看到一個很深刻的討論,為何 LLM 的輸出大部分都是正確的廢話,這是因為 LLM 的訓練方式決定了它的預設輸出是共識(context-infrastructure)。每一步 next token prediction 選的都是機率最高的 token,RLHF 進一步懲罰有爭議的回答。所以 AI 的天花板是"大多數人會認同的答案"。這個答案正確,但平庸。
你餵 AI 一堆產業報告,它能寫出一份像模像樣的綜述。但你餵它一個資深投資人 20 年累積的判斷框架,它能寫出一份有觀點的分析。差距在於後者攜帶了"個人意見",而恰恰是這種有方向的意見讓分析有了銳度。我想 Grok (OpenAI & Antropic 也正在進行) 也打算做類似的事情吧
謝謝KP無私分享